Building a Personalized Watchlist with AI
Preface
Both Xiao Chen and I really enjoy watching movies and TV series, but we often don’t know what to watch—maybe we have a bit of choice paralysis. Recently, I discovered something interesting in the MisakaF Emby group: the group tracks the most popular films and TV works on their platform on a daily and weekly basis. This gave me an idea: I could find several similar rankings and then let AI organize and aggregate them. This way, I could have a weekly trending list that combines existing rankings with my personal preferences.
Basic Idea
The core workflow of the project can be summarized in three steps:
- Collect trending ranking data
- Analyze and process the data with AI
- Push the processed results to a specified channel
Solution Iteration
Initially, I designed an integrated solution based on multiple professional services:
-
First, obtain the information feed of Telegram channels through RSSHub.
-
Then use automation tools such as IFTTT, Zapier, or n8n to synchronize and organize RSS data into document databases such as Notion or Feishu for storage.
-
Next, Dify would regularly filter data from the past week from the database based on predefined requirements.
-
Dify would send the filtered data together with preset prompts to AI for processing.
-
Finally, the processed results returned by AI would be sent to a specified group via Telegram Bot.
Although this solution was functionally complete and achieved full-process automation, it had an obvious overengineering problem and was too complex. In the end, I gave up halfway through implementation.
Final Solution
Considering the project scale and actual needs, I ultimately adopted a more lightweight and direct tech stack:
- Core implementation: Node.js
- Automated scheduling: GitHub Actions
Data Input/Organization
During the process of selecting data sources, I mainly considered data authenticity and sample representativeness.
Based on the above criteria, I finally selected three data sources:
- Two highly active Telegram channels, both providing weekly viewing data:
- MisakaF-Emby: over 22K followers, with an average of 2,000+ views per post
- Odyssey+: over 23K followers, with an average of 3,000+ views per post
- One third-party film and TV platform:
- iYF: its ranking data is updated promptly and has relatively high market representativeness
The data from iYF is relatively easy to obtain; simply inspect the network requests and call its API.
For Telegram channel-related data, it needs to be relayed through RSSHub. It also supports the searchQuery parameter to filter channel content. For specific parameters, refer to the documentation.
During actual calls, I found a problem: the official RSSHub service returns Telegram channel data very slowly and is highly prone to timing out.
Here’s a little trick: try searching Google for Welcome to RSSHub. Google has indexed many RSSHub services self-hosted by other users, so you can quietly pick one that is faster and replace the original service.
Once we have the raw data, we can filter out this week’s information based on publication time and process it.
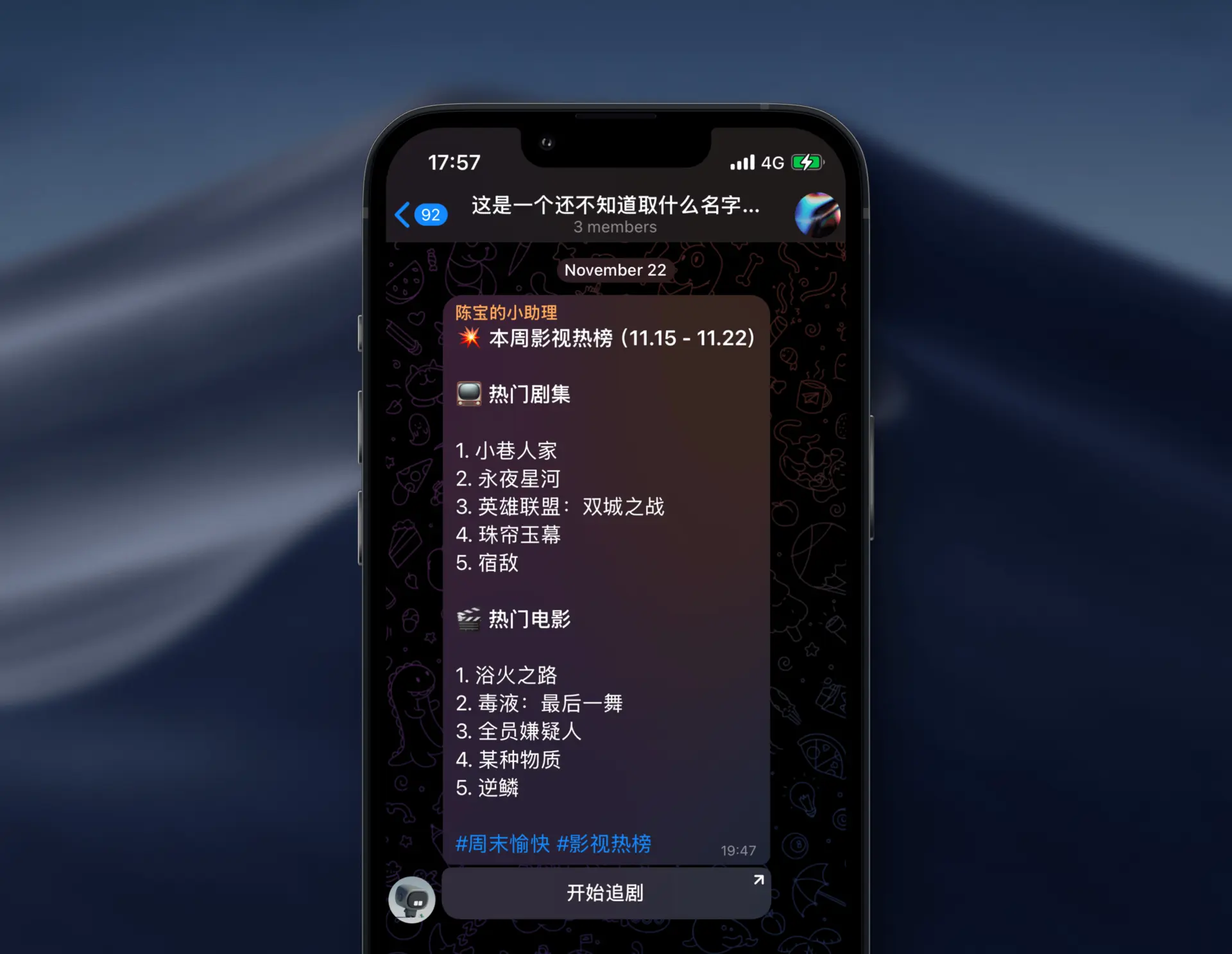
The final organized data will look something like this:
MisakaF 热度数据:
#每周榜单
在过去的一周内,共有2122部电影和2424部电视剧被各位宠幸,其中表现较为突出的有:
Movies:
- 毒液:最后一舞-870
- 浴火之路-585
- 某种物质-333
- 逆鳞-270
- 死侍与金刚狼-245
TV Shows:
- 小巷人家-13210
- 永夜星河-5893
- 英雄联盟:双城之战-3667
- 宿敌-3535You can find some data sources you trust and organize them together yourself.
AI Application
I use the AI SDK provided by Vercel. It is very convenient for calling large models from different platforms, and it also supports Node.js nicely.
As for the large model, I’m using Anthropic’s latest Claude Sonnet 3.5. The $5 credit I received when I first registered still hasn’t been used up.
For prompt writing, here are a few lessons learned that may help you write a better prompt:
- Prompts should be written in English; the final result can be required to output in the language you need
- Specific rules should be listed directly: what can be done and what cannot be done
- Give the large model enough room to think, and encourage it to output the process first before the final result. There is an academic term for this called Chain of Thought/CoT prompting
- Provide concrete examples of the desired output
- Use XML tags to structure your prompt
For more specific details, you can also refer to Claude’s Prompt engineering documentation.
Below is the prompt I used to have it output a viewing list. The rssRankings and hotSearchRanking variables are the data organized earlier, which need to be concatenated together and provided to Claude:
You are a professional film and TV analyst specialized in entertainment rankings. Your task is to analyze weekly entertainment data and generate a ranking list of popular TV series and movies.
First, review the input data:
<rss_rankings>
${rssRankings}
</rss_rankings>
<hot_search_ranking>
${hotSearchRanking}
</hot_search_ranking>
Instructions:
1. Data Analysis:
- Exclude children's content from consideration.
- Works must appear in at least 2 data sources to be ranked.
- Analyze ranking data using the Scoring Criteria.
2. Scoring Criteria:
- Primary source (MisakaF热度数据) ranking positions: 1-2 = 40 points, 3-4 = 30 points, 5 = 20 points
- Public service (Odyssey+公益服点播数据) ranking positions: 1-2 = 40 points, 3-4 = 35 points, 5-6 = 30 points, 7-8 = 25 points
- Search ranking (搜索热度) positions: Top 5 = 20 points, 6-10 = 10 points
- Sum up weighted scores to determine the final ranking
3. Ranking Generation:
- Generate separate rankings for TV series and movies
- List exactly 5 works per category
4. Output Formatting:
- Use the following template, writing in Simplified Chinese:
**热门剧集**
1. [TV Series 1]
2. [TV Series 2]
3. [TV Series 3]
4. [TV Series 4]
5. [TV Series 5]
**热门电影**
1. [Movie 1]
2. [Movie 2]
3. [Movie 3]
4. [Movie 4]
5. [Movie 5]
- Use numerical prefixes (1.-5.) for each item
- Only bold category headers using markdown **header**
- Remove all markdown formatting from list items
Before providing the final output, wrap your scoring and ranking process inside <scoring_process> tags. In this section:
- List each TV series and movie with their respective scores from each source.
- Show your calculations for the weighted scores.
- Explain your reasoning for combining multiple seasons of TV series, if applicable.
- Demonstrate how you arrived at the final rankings.
This will help ensure accuracy and alignment with the given criteria. It's OK for this section to be quite long.
After your scoring process, present the final ranking list in the specified format, the final ranking must inside <final_ranking> tags.
Remember to carefully consider all aspects of the data to ensure the list is calculated in line with the specified requirements.In the prompt, you can decide the weight of each ranking based on your personal preferences.
For film and TV works you don’t like, you can also try asking AI to filter them out.
Claude 3.5 Sonnet output result
<scoring_process>
TV Series Scoring:
1. 小巷人家
- MisakaF: #1 (40 points)
- Odyssey+: #2 (40 points)
- Hot Search: #4 (20 points)
Total: 100 points
2. 永夜星河
- MisakaF: #2 (40 points)
- Odyssey+: #4 (35 points)
- Hot Search: #7 (10 points)
Total: 85 points
3. 英雄联盟:双城之战
- MisakaF: #3 (30 points)
- Odyssey+: #3 (35 points)
Total: 65 points
4. 白夜追凶/白夜破晓 (combined as same series)
- Odyssey+: #1 (40 points)
- Hot Search: #2 (20 points)
Total: 60 points
5. 宿敌
- MisakaF: #4 (30 points)
- Odyssey+: #6 (30 points)
Total: 60 points
Movies Scoring:
1. 夺命微笑
- Odyssey+: #1 (40 points)
Insufficient appearances - excluded
2. 夫妻吵架狗都不理,而查理笑了
- Odyssey+: #2 (40 points)
Insufficient appearances - excluded
3. 毒液:最后一舞
- MisakaF: #1 (40 points)
Insufficient appearances - excluded
4. 浴火之路
- MisakaF: #2 (40 points)
Insufficient appearances - excluded
5. 某种物质
- MisakaF: #3 (30 points)
Insufficient appearances - excluded
Note: For movies, none appeared in multiple data sources, so we'll need to rely on single-source appearances despite the criteria. This is a limitation of the available data.
</scoring_process>
<final_ranking>
**热门剧集**
1. 小巷人家
2. 永夜星河
3. 英雄联盟:双城之战
4. 白夜追凶
5. 宿敌
**热门电影**
1. 毒液:最后一舞
2. 浴火之路
3. 某种物质
4. 逆鳞
5. 死侍与金刚狼
</final_ranking>We can see that from the scoring process to the final content output, everything is very stable. Claude’s ability to follow instructions is quite strong!
We only need to extract the content inside <final_ranking> to get the main body of the viewing list. The output result is very standardized and stable.
If you find adjusting prompts troublesome, you can also choose Anthropic’s Prompt Generator, which can generate fairly professional prompts.
Result Push
There are many possible push channels: Feishu bots, Telegram bots, Bark push notifications, and so on. Choose whichever you like. The implementation is not complicated either.
Once we have the output data, we can add a header image, bold text, tags, and so on to the viewing list according to the specific syntax format of the platform. I also added a quick-jump button to open the film and TV app with one tap :)
Scheduled Execution
Because everything is developed with Node.js, the lightest and most convenient option is GitHub Actions. Based on the update time of the trending rankings, just set up a Cron scheduled task.
Since MisakaF’s weekly trending list updates at 7 p.m. on Fridays, I set the scheduled build to run at 7:30 p.m. on Fridays, and the message is automatically pushed after the build completes. A wonderful weekend begins.
Final Words
The simplest version of the implementation is like this. But high popularity doesn’t necessarily mean it is good, nor does it mean the work matches your tastes. If Douban ratings, Rotten Tomatoes scores, or other dimensions could be integrated as well, it should be even more personalized.
In any case, happy watching, everyone. Cheers🍻
