告别选片困扰:用 AI 打造个性观影榜单
前言
我和小陈两个人挺喜欢看电影、电视剧,但常常会不知道看点啥,可能有点选择困难症。最近,我在 MisakaF Emby 群组发现了个好玩的东西:这群组会统计他们平台上每日、每周最受欢迎的影视作品。这让我萌生了一个想法:我可以多找几个类似的榜单,然后让 AI 整理聚合一下。这样,我每周也能有一个结合现有榜单以及个人偏好的热榜了。
基本思路
项目的核心流程可概括为三个步骤:
- 采集热榜数据
- 通过 AI 进行数据分析和处理
- 将处理结果推送至指定渠道
方案迭代
最初设计了一个基于多个专业服务的集成方案:
-
首先通过 RSSHub 获取 Telegram 频道的信息源。
-
接着使用 IFTTT、Zapier 或 n8n 等自动化工具,将 RSS 数据同步整理到 Notion 或飞书等文档数据库中存储。
-
然后由 Dify 根据设定的需求,定时从数据库中筛选近一周的数据。
-
Dify 将筛选后的数据连同预设的提示词一起发送给 AI 进行处理。
-
最后,将 AI 返回的处理结果通过 Telegram Bot 发送到指定的群组中。
这种方案虽然功能完整,实现了全流程自动化,但存在明显的过度设计问题,过于复杂,最终也只是实践到一半就放弃了。
最终方案
考虑到项目规模和实际需求,我最终采用了更加轻量且直接的技术栈:
- 核心实现:Node.js
- 自动化调度:GitHub Actions
数据输入/整理
在数据源筛选过程中,我主要考虑数据真实性、样本代表性。
基于上述标准,最终确定了三个数据来源:
- 两个具有高活跃度的 Telegram 频道,均提供每周观影数据:
- MisakaF-Emby:关注用户超过 22K,单条推送平均阅读量 2,000+
- Odyssey+:关注用户超过 23K,单条推送平均阅读量 3,000+
- 一个第三方影视平台:
- 爱壹帆:其排行榜数据更新及时、具有较高的市场代表性
爱壹帆数据获取相对容易,查看网络请求调用其 API 即可。
Telegram 频道相关的数据则需要使用 RSSHub 中转一下,其还支持 searchQuery 参数对频道内容进行过滤,具体参数可查看文档。
在实际调用中发现了一个问题, RSSHub 官方的服务返回 Telegram 频道数据会很慢,非常容易超时。
这时候告诉大家一个奇技淫巧,尝试 Google 搜索 Welcome to RSSHub,Google 收录了很多网友自己搭建的 RSSHub 服务,可以悄悄咪咪选一下哪个速度更快,替换掉原有服务。
原始数据都有了,我们就可以根据发布时间筛选出本周的信息,并对其进行处理。
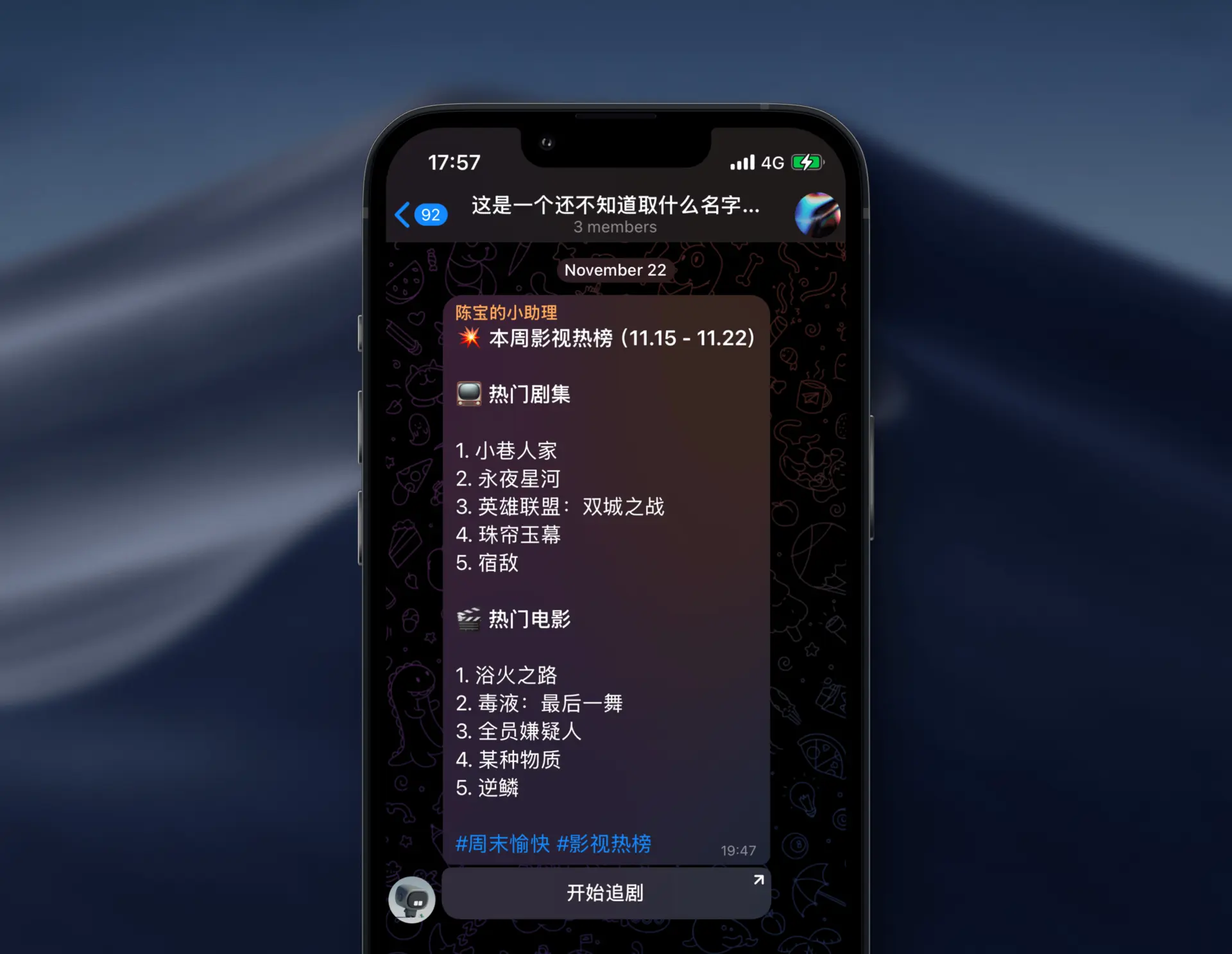
最终整理后的数据会类似这样:
MisakaF 热度数据:
#每周榜单
在过去的一周内,共有2122部电影和2424部电视剧被各位宠幸,其中表现较为突出的有:
Movies:
- 毒液:最后一舞-870
- 浴火之路-585
- 某种物质-333
- 逆鳞-270
- 死侍与金刚狼-245
TV Shows:
- 小巷人家-13210
- 永夜星河-5893
- 英雄联盟:双城之战-3667
- 宿敌-3535各位可以自己找一些自己认可的数据源整理到一起。
AI 应用
我使用的是 Vercel 提供的 AI SDK,调用不同平台的大模型非常方便,正好其也支持 Node.js。
大模型方面,我是使用的 Anthropic 最新的 Claude Sonnet 3.5,刚注册时候送的 5 美元额度到现在也还没有用完。
而在提示词编写部分,有几点经验心得,或许能帮助你写一份更好的提示词:
- 需要使用英文编写提示词,最终结果可以考虑让其输出你需求的语言
- 需要直接列出具体的规则:什么能做、什么不能做
- 给予大模型足够的思考空间,鼓励其先输出过程,再最后输出结果。这有个学术名字叫思维链(Chain of thought/CoT prompting)
- 给予大模型具体的输出结果示例
- 使用 XML 标签来结构化您的提示
更加具体详细的你也可以参考 Claude 编写的 Prompt engineering 文档。
下面是我让其输出观影清单的提示词,其中 rssRankings、hotSearchRanking 变量是前面整理出来的数据,需要拼凑在一起提供给 Claude:
You are a professional film and TV analyst specialized in entertainment rankings. Your task is to analyze weekly entertainment data and generate a ranking list of popular TV series and movies.
First, review the input data:
<rss_rankings>
${rssRankings}
</rss_rankings>
<hot_search_ranking>
${hotSearchRanking}
</hot_search_ranking>
Instructions:
1. Data Analysis:
- Exclude children's content from consideration.
- Works must appear in at least 2 data sources to be ranked.
- Analyze ranking data using the Scoring Criteria.
2. Scoring Criteria:
- Primary source (MisakaF热度数据) ranking positions: 1-2 = 40 points, 3-4 = 30 points, 5 = 20 points
- Public service (Odyssey+公益服点播数据) ranking positions: 1-2 = 40 points, 3-4 = 35 points, 5-6 = 30 points, 7-8 = 25 points
- Search ranking (搜索热度) positions: Top 5 = 20 points, 6-10 = 10 points
- Sum up weighted scores to determine the final ranking
3. Ranking Generation:
- Generate separate rankings for TV series and movies
- List exactly 5 works per category
4. Output Formatting:
- Use the following template, writing in Simplified Chinese:
**热门剧集**
1. [TV Series 1]
2. [TV Series 2]
3. [TV Series 3]
4. [TV Series 4]
5. [TV Series 5]
**热门电影**
1. [Movie 1]
2. [Movie 2]
3. [Movie 3]
4. [Movie 4]
5. [Movie 5]
- Use numerical prefixes (1.-5.) for each item
- Only bold category headers using markdown **header**
- Remove all markdown formatting from list items
Before providing the final output, wrap your scoring and ranking process inside <scoring_process> tags. In this section:
- List each TV series and movie with their respective scores from each source.
- Show your calculations for the weighted scores.
- Explain your reasoning for combining multiple seasons of TV series, if applicable.
- Demonstrate how you arrived at the final rankings.
This will help ensure accuracy and alignment with the given criteria. It's OK for this section to be quite long.
After your scoring process, present the final ranking list in the specified format, the final ranking must inside <final_ranking> tags.
Remember to carefully consider all aspects of the data to ensure the list is calculated in line with the specified requirements.在提示词中,你可以根据个人偏好来决定各个榜单的权重。
不喜欢的影视作品,你也可以尝试让 AI 进行过滤。
Claude 3.5 Sonnet 输出结果
<scoring_process>
TV Series Scoring:
1. 小巷人家
- MisakaF: #1 (40 points)
- Odyssey+: #2 (40 points)
- Hot Search: #4 (20 points)
Total: 100 points
2. 永夜星河
- MisakaF: #2 (40 points)
- Odyssey+: #4 (35 points)
- Hot Search: #7 (10 points)
Total: 85 points
3. 英雄联盟:双城之战
- MisakaF: #3 (30 points)
- Odyssey+: #3 (35 points)
Total: 65 points
4. 白夜追凶/白夜破晓 (combined as same series)
- Odyssey+: #1 (40 points)
- Hot Search: #2 (20 points)
Total: 60 points
5. 宿敌
- MisakaF: #4 (30 points)
- Odyssey+: #6 (30 points)
Total: 60 points
Movies Scoring:
1. 夺命微笑
- Odyssey+: #1 (40 points)
Insufficient appearances - excluded
2. 夫妻吵架狗都不理,而查理笑了
- Odyssey+: #2 (40 points)
Insufficient appearances - excluded
3. 毒液:最后一舞
- MisakaF: #1 (40 points)
Insufficient appearances - excluded
4. 浴火之路
- MisakaF: #2 (40 points)
Insufficient appearances - excluded
5. 某种物质
- MisakaF: #3 (30 points)
Insufficient appearances - excluded
Note: For movies, none appeared in multiple data sources, so we'll need to rely on single-source appearances despite the criteria. This is a limitation of the available data.
</scoring_process>
<final_ranking>
**热门剧集**
1. 小巷人家
2. 永夜星河
3. 英雄联盟:双城之战
4. 白夜追凶
5. 宿敌
**热门电影**
1. 毒液:最后一舞
2. 浴火之路
3. 某种物质
4. 逆鳞
5. 死侍与金刚狼
</final_ranking>我们可以看到从评分过程,到最后的内容输出,都非常的稳定,Claude 的指令跟随能力相当强!
我们只需要提取 <final_ranking> 中的内容,就可以得到观影清单的主体内容。输出的结果非常标准、稳定。
如果你觉得调整提示词比较麻烦,你也可以选择 Anthropic 出品的 Prompt Generator,能够生成相当专业的提示词。
结果推送
推送渠道就多种多样了,飞书机器人、Telegram 机器人、Bark 推送等等。任君挑选。实现也不复杂。
有了输出数据之后,我们就可以根据平台具体的语法格式,给观影清单加入头图、加粗、标签等。我还另加了一个快捷跳转影视软件的按钮,一键启动:)
定时运行
因为全部使用的是 Node.js 开发。所以,最轻量、最方便的就是 Github Action。根据热榜更新的时间,设置个 Cron 定时任务即可。
因为 MisakaF 每周热榜更新时间是周五晚上七点,所以我设置定时构建在周五七点半,构建完毕自动推送消息。开启美好的一个周末。
写在最后
最简单版本的实现就是这样。但是热度高其实也不代表其好看、也不代表这作品符合你的喜好。如果可以再集成豆瓣评分、烂番茄评分或其他维度的话,应该可以更加个性化。
不管如何,祝大家观影愉快 Cheers🍻
